Inscrivez-vous maintenant pour un meilleur devis personnalisé!































This blog post was authored by Veronica Valeros and Lukas Machlica
Malicious actors are constantly evolving their techniques in order to evade detection. It is not only the sophistication or the rapid pace of change that is challenging us as defenders, but the scale of attacks. With the continuous flood of threats that we are facing, detection is just the first step. In order to keep our organizations healthy, prioritizing threats is key.
 Figure 1: Cognitive Threat Analytics (CTA) Health Status Dashboard shows which threats require immediate action from incident responders. Prioritization has become key for keeping our organizations healthy.
Figure 1: Cognitive Threat Analytics (CTA) Health Status Dashboard shows which threats require immediate action from incident responders. Prioritization has become key for keeping our organizations healthy.In our previous blog, Cognitive Threat Analytics: Turn Your Proxy Into Security Device, we showed how CTA detects breaches and malware that already bypassed the security perimeter of our organizations. Detecting the malicious traffic alone is not enough. Organizations need to understand the context in order to effectively prioritize and remediate those incidents. And when it comes to remediating security breaches, time is of the essence.
In this blog post we present how we improved CTA threat classification, now able to communicate the intent of every new finding by incorporating an extra layer of intelligence into the CTA detection chain [1]. CTA is now able to automatically classify and prioritize malicious traffic in specific threat categories from banking trojans, click-fraud and malware distribution to ad-injectors, money scams and malicious advertising campaigns. This blog explores how we are building a reliable training set in a big data environment, how we use it to train a new decision forest classifier and how we created a learning loop which led to a significant increase in the number of detections.
CTA processes billions of HTTP & HTTPS requests every day. We extract feature vectors, and use them to build the training set for the classifiers. However, three major issues arise when working with this huge amount of data:
To deal with the first two issues, we need to reduce the amount of data in a way that the final dataset is more balanced and the computational costs are reduced. A dataset is considered balanced when it contains, in this context, a similar number of malicious and benign requests. To achieve this goal we take advantage of the Anomaly Detection Layer in CTA [1]. The Anomaly Detection Layer can be seen as a clever sampling tool capable of filtering out most of the ordinary traffic as illustrated in Figure 2. Using this component we are able to drastically reduce the input data and keep only a small percentage of the most interesting and important requests. This leads to a more balanced ratio of malicious and benign requests. The anomalous requests, are much likely to lie in the classification-relevant part of the feature space leading to well defined decision borders, which will be discussed later.
 Figure 2: Filtering of the input data (telemetry). Only the most anomalous traffic is kept based on the anomaly score provided by the anomaly detection layer, reducing and balancing the remaining data.
Figure 2: Filtering of the input data (telemetry). Only the most anomalous traffic is kept based on the anomaly score provided by the anomaly detection layer, reducing and balancing the remaining data.The third issue has a direct impact on the precision of the resulting classifier. Since network data cannot be fully labeled, we can only tell with certainty what is malicious and what is benign for a small portion of requests, which we call samples. How do we solve this? Typical methods use only labeled data for training. While these approaches can have good performance on the labeled dataset, the performance often does not hold when classifying the full unlabeled telemetry. This approach may result in weak decision boundaries as illustrated in Figure 3. In order to have a diverse background training set, we also include the unlabeled samples for the training. While this approach may lead to drops in the recall of the classifier, it results in stronger decision boundaries and significantly boosting the precision of detections.
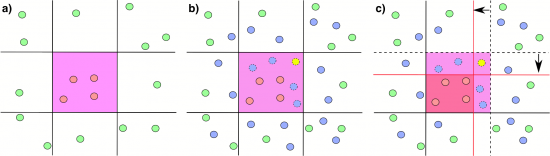 Figure 3: Feature space. Green and red circles represent labeled legitimate and malicious samples, while blue and yellow are legitimate and malicious but yet unlabeled samples. First image (a) depicts the decision borders if only the labeled samples are used for the training. Once the unlabeled samples are included (b), the decision boundaries are found to be inaccurate, therefore the precision of the classifier decreases. If we use also the unlabeled samples for the training, we get much stronger decision boundaries yielding high precision of the detection (c).
Figure 3: Feature space. Green and red circles represent labeled legitimate and malicious samples, while blue and yellow are legitimate and malicious but yet unlabeled samples. First image (a) depicts the decision borders if only the labeled samples are used for the training. Once the unlabeled samples are included (b), the decision boundaries are found to be inaccurate, therefore the precision of the classifier decreases. If we use also the unlabeled samples for the training, we get much stronger decision boundaries yielding high precision of the detection (c).As we mentioned above, we use all labeled data available and the full unlabeled data for training. Where do we get the set of labeled malicious samples? We use the Confirmed Threats provided by the third layer of CTA: the relationship modeling layer [1]. This layer correlates information across our global intelligence in order to find common attack patterns and malware behaviors in different organizations. Each confirmed threat is assigned a specific malware category and a risk score which are further leveraged for training data. We will get back to this in the learning loop.
Decision forests are a set of numerous decision trees where the final decision of the forest is given by voting of individual trees in the entire group (see figure 4 for an example). To improve the robustness, precision and generalization performance of the classifier, we use the favored random forest implementation. As a binary classifier (malicious vs. legit) the random forests are already deployed in the CTA Event classification layer [1] for classification of general communication patterns such as DGA and other C&C behaviors.
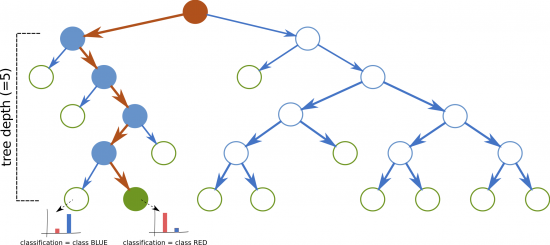 Figure 4: Example of a decision tree with depth 5. The tree is traversed from the root node (brown circle) down to a leaf node (green circle). Decision path is depicted by full circles. The classification is given by the class with majority of samples that end up in the leaf node during the training phase.
Figure 4: Example of a decision tree with depth 5. The tree is traversed from the root node (brown circle) down to a leaf node (green circle). Decision path is depicted by full circles. The classification is given by the class with majority of samples that end up in the leaf node during the training phase.The Superforest classifier is a special type of multi-class classifier. Three key characteristics distinguishes it from the previous ones:
As we mentioned in the beginning, detecting malicious incidents alone is no longer enough. The Superforest classifier is able to classify new incidents with a deeper level of detail, which is extremely valuable when it comes to prioritizing incidents, and using this information to remediate threats in an organization. Figure 5 exemplifies the benefits of such classifier.
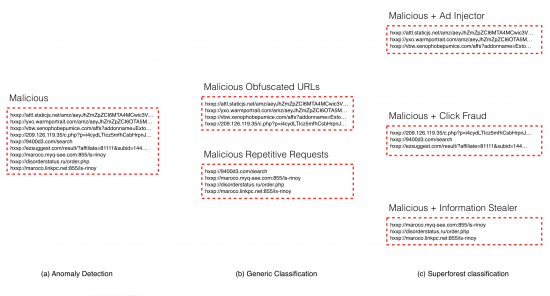 Figure 5: The anomaly detection layer is able to distinguish benign from legitimate (a). Normal classifiers can go further and group malicious behaviors by common characteristics such as the ones depicted in (b). The Superforest classifier is able to provide even more detailed information of each detection (c), which is extremely valuable at the time of prioritizing and remediating threats.
Figure 5: The anomaly detection layer is able to distinguish benign from legitimate (a). Normal classifiers can go further and group malicious behaviors by common characteristics such as the ones depicted in (b). The Superforest classifier is able to provide even more detailed information of each detection (c), which is extremely valuable at the time of prioritizing and remediating threats.The learning loop is where all these pieces fit together. The Superforest and other classifiers, part of the CTA Event Classification Layer [1], produce novel detections. The next layer, Relationship Modeling [1], correlates this new findings increasing the number of Confirmed Threats. As we mentioned before, Confirmed Threats are used to train the classifiers. The increase on Confirmed Threats increases the available data for training causing an increase of the recall of the Superforest classifier each time it is retrained. The learning loop is depicted in Figure 6.
 Figure 6: Classification and learning loop.
Figure 6: Classification and learning loop.In order to demonstrate the power of the enhanced CTA Event classification layer, we tracked the performance of the learning loop for 3 weeks. Precision of the classification was higher than 95% in all the cases. Figure 7 depicts a click fraud example where the yellow area shows the number of incidents per day given by the Relationship Modeling layer and the blue area represents the number of incidents per day as a result of the learning loop and the Superforest classifier.
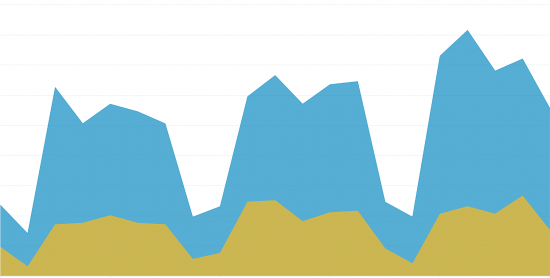 Figure 7: The figure depicts the number of incidents per day given the relationship modelling (yellow) and the whole classification loop with the deployed Superforest classifier (blue). We can observe significant increase in the detections (doubled or even tripled in some cases) over the whole observed timeline. Note that the significant drops in the number of detections are because of the weekends.
Figure 7: The figure depicts the number of incidents per day given the relationship modelling (yellow) and the whole classification loop with the deployed Superforest classifier (blue). We can observe significant increase in the detections (doubled or even tripled in some cases) over the whole observed timeline. Note that the significant drops in the number of detections are because of the weekends.The amount of threats organizations have to deal with present a challenge, for organizations and for security solutions. Identifying malicious traffic is table stakes and context is needed so organizations can prioritize the incidents, take action and reduce the potential damage caused by these threats. The Superforest multi-class classifier is leveraging both labeled and unlabeled data to classify incidents with a high level of detail. This approach is only possible by having a good set of training data, which implies solving three key issues: imbalance of data, computational costs and scarce labels. Cognitive Threat Analytics is able to go further, joining all pieces together in a learning loop which can improve itself over time boosting the performance of the detections.
To request a free evaluation that will uncover command and control communications lurking in your environment, visit: https://cognitive.cisco.com/
Read more about Cognitive Threat Analytics research:
Watch more about CTA as part of Cisco Security solutions:
[1] Valeros, V., Somol, P., Reh
 Tags chauds:
Cisco Cognitive Threat Analytics
big data analytics
Cognitive Intelligence
CTA
Tags chauds:
Cisco Cognitive Threat Analytics
big data analytics
Cognitive Intelligence
CTA
Inscrivez-vous par courriel maintenant pour le Stock de Promotion hebdomadaire
100% free, Unsubscribe any time!
Add 1: Room 605 6/F FA YUEN Commercial Building, 75-77 FA YUEN Street, Mongkok KL, HongKong Add 2: Room 405, Building E, MeiDu Building, Gong Shu District, Hangzhou City, Zhejiang Province, China
Whatsapp/Tel: +8618057156223 Tél. : + 33 (0) 3 88 88 20: 0086 571 86729517 Tel à HK: 00852 66181601
Courriel:: info@hi-network.com
 English
English Pусский
Pусский Français
Français Español
Español Português
Português Fast Shipping To HONGKONG
Fast Shipping To HONGKONG

