Inscrivez-vous maintenant pour un meilleur devis personnalisé!































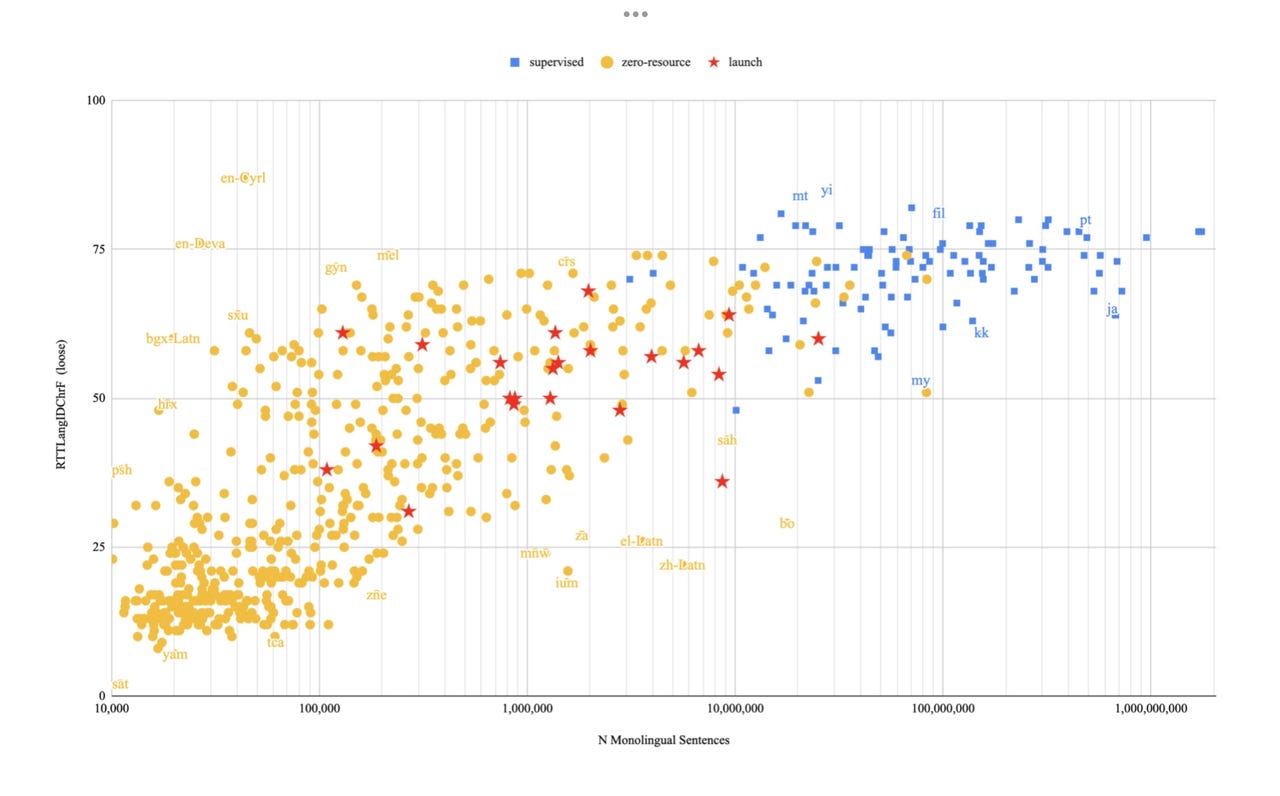
Scores for languages when translating from English and back to English again, correlated to how many sample sentences the language has. Toward the right side, higher numbers of example sentences result in better scores. There are outliers, such as English in Cyrillic, which has very few examples but translates well.
Bapna et al., 2022What do you do after you have collected writing samples for a thousand languages for the purpose of translation, and humans still rate the resulting translations a fail?
Examine the failures, obviously.
And that is the interesting work that Google machine learning scientists related this month in a massive research paper on multi-lingual translation, "Building Machine Translation Systems for the Next Thousand Languages," posted on Arxiv.
"Despite tremendous progress in low-resource machine translation, the number of languages for which widely-available, general-domain MT systems have been built has been limited to around 100, which is a small fraction of the over 7000+ languages that are spoken in the world today," write lead author Ankur Bapna and colleagues.
The paper describes a project to create a data set of over a thousand languages, including so-called low-resource languages, those that have very few documents to use as samples for training machine learning.
Also: DeepMind: Why is AI so good at language? It's something in language itself
While it is easy to collect billions of example sentences for English, and over a hundred million example sentences for Icelandic, for example, the language kalaallisut, spoken by about 56,000 people in Greenland, has fewer than a million extant example sentences readily available in online texts; and the Kelantan-Pattani Malay language, spoken by about five million people in Malaysia and Thailand, has fewer than 10,000 example sentences readily available.
To compile a data set for machine translation for such low-resource languages, Bapna and two dozen colleagues first created a tool to scour the Internet and identify texts in low-resource languages. The authors use a number of machine learning techniques to extend a system called LangID, which comprises techniques for identifying whether a Web text belongs to a given language. That is a rather involved process of eliminating false positives.
After scouring the Web with LangID techniques, the authors were able to assemble "a dataset with corpora for 1503 low-resource languages, ranging in size from one sentence (Mape) to 83 million sentences (Sabah Malay)."
The scientists boiled that list down to 1,057 languages "where we recovered more than 25,000 monolingual sentences (before deduplication)," and combined that group of samples with the much larger data for 83 "high-resource languages" such as English.
Also: AI: The pattern is not in the data, it's in the machine
They then tested their data set by running experiments to translate between the languages in that set. They used various versions of the ubiquitous Transformer neural net for language modeling. In order to test performance of translations, the authors focused on translating to and from English with 38 languages for which they obtained example true translations, including kalaallisut
That's where the most interesting part comes in. The authors asked human reviewers who are native speakers of low-resource languages to rate the quality of translations for 28 languages on a scale of zero to six, with zero being "nonsense or wrong language" and six, "perfect."
Also: Facebook open sources tower of Babel, Klingon not supported
The results are not great. Out of 28 languages translated from English, 13 were rated below 4 on the scale in terms of quality of translation. That would imply almost half of the English to target translations were mediocre.
The authors have a fascinating discussion starting on page 23 of what seems to have gone wrong in those translations with weak ratings.
"The biggest takeaway is that automatic metrics overestimate performance on related dialects," they write, meaning, scores the machine assigns to translations, such as the widely used BLEU score, tend to give credit where the neural network is simply translating into a wrong language that is like another language. For example, "Nigerian Pidgin (pcm), a dialect of English, had very high BLEU and CHRF scores, of around 35 and 60 respectively. However, humans rated the translations very harshly, with a full 20% judged as 'Nonsense/Wrong Language', with trusted native speakers confirming that the translations were unusable."
"What's happening here that the model translates into (a corrupted version of ) the wrong dialect, but it is close enough on a character n-gram level" for the automatic benchmark to score it high, they observe.
"This is the result of a data pollution problem," they deduce, "since these languages are so close to other much more common languages on the web [...] the training data is much more likely to be mixed with either corrupted versions of the higher-resource language, or other varieties."
Examples of translations with correct terms in blue and mistranslations in yellow. The left-hand column shows the code for which language is being translated into, using the standard BCP-47 tags.
Bapna et al., 2022Also: Google uses MLPerf competition to showcase performance on gigantic version of BERT language model
And then there are what the authors term "characteristic error modes" in translations, such as "translating nouns that occur in distributionally similar contexts in the training data," such as substituting "relatively common nouns like 'tiger' with another kind of animal word, they note, "showing that the model learned the distributional context in which this noun occurs, but was unable to acquire the exact mappings from one language to another with enough detail within this category."
Such a problem occurs with "animal names, colors, and times of day," and "was also an issue with adjectives, but we observed few such errors with verbs. Sometimes, words were translated into sentences that might be considered culturally analogous concepts -for example, translating 'cheese and butter' into 'curd and yogurt' when translating from Sanskrit."
Also: Google's latest language machine puts emphasis back on language
The authors make an extensive case for working closely with native speakers:
We stress that where possible, it is important to try to build relationships with native speakers and members of these communities, rather than simply interacting with them as crowd-workers at a distance. For this work, the authors reached out to members of as many communities as we could, having conversations with over 100 members of these communities, many of whom were active in this project.
An appendix offers gratitude to a long list of such native speakers.
Despite the failures cited, the authors conclude the work has successes of note. In particular, using the LangID approach to scour the web, "we are able to build a multilingual unlabeled text dataset containing over 1 million sentences for more than 200 languages and over 100 thousand sentences in more than 400 languages."
And the work with Transformer models convinces them that "it is possible to build high quality, practical MT models for long-tail languages utilizing the approach described in this work."
 Tags chauds:
Intelligence artificielle
Innovation et Innovation
Tags chauds:
Intelligence artificielle
Innovation et Innovation
Inscrivez-vous par courriel maintenant pour le Stock de Promotion hebdomadaire
100% free, Unsubscribe any time!
Add 1: Room 605 6/F FA YUEN Commercial Building, 75-77 FA YUEN Street, Mongkok KL, HongKong Add 2: Room 405, Building E, MeiDu Building, Gong Shu District, Hangzhou City, Zhejiang Province, China
Whatsapp/Tel: +8618057156223 Tél. : + 33 (0) 3 88 88 20: 0086 571 86729517 Tel à HK: 00852 66181601
Courriel:: info@hi-network.com
 English
English Pусский
Pусский Français
Français Español
Español Português
Português Fast Shipping To HONGKONG
Fast Shipping To HONGKONG

