Inscrivez-vous maintenant pour un meilleur devis personnalisé!






























You may have noticed that last week, Microsoft and Nvidia announced they had trained "the world's largest and most powerful generative language model," known as "Megatron-Turing NLG 530B," asZDNet'sChris Duckett reported.
The model, in this case, is a neural network program based on the "Transformer" approach that has become widely popular in deep learning. Megatron-Turing is able to produce realistic-seeming text and also perform on various language tests such as sentence completion.
The news was somewhat perplexing in that Microsoft had already announced a program a year ago that seemed to be bigger and more powerful. While Megatron-Turing NLG 530B uses 530 billion neural "weights," or parameters, to compose its language model, what's known as "1T" has one trillion parameters.
Microsoft's blog post explaining Megatron-Turing linked to the Github repo maintained by Nvidia's Jared Casper, where the various different language models are listed, along with stats. Those stats show that not only is 1T bigger than Megatron-Turing NLG 530B, it has higher numbers for every performance figure, including the peak tera-FLOPs, or trillions of floating point operations per second, that were achieved.
So how can Megatron-Turing NLG 530B be the biggest if 1T is bigger by every measure? To resolve the matter,ZDNetspoke with Nvidia's Paresh Kharya, senior director of product marketing and management.
The key is that 1T was never "trained to convergence," a term that means that the model has been fully developed and can now be used for performing inference, the stage where predictions are made. Instead, 1T went through a limited number of training runs, said Kharya, known as "epochs," which do not lead to convergence.
As Kharya explains, "Training large models to convergence takes weeks and even months depending on the size of supercomputer used." The table on the GitHub page is listing what are called "scaling studies," which create a measure of what kind of performance can be obtained even without training a model to convergence.
Such studies "can be done by doing partial training runs for a few minutes at different scale and model sizes," Kharya toldZDNet.
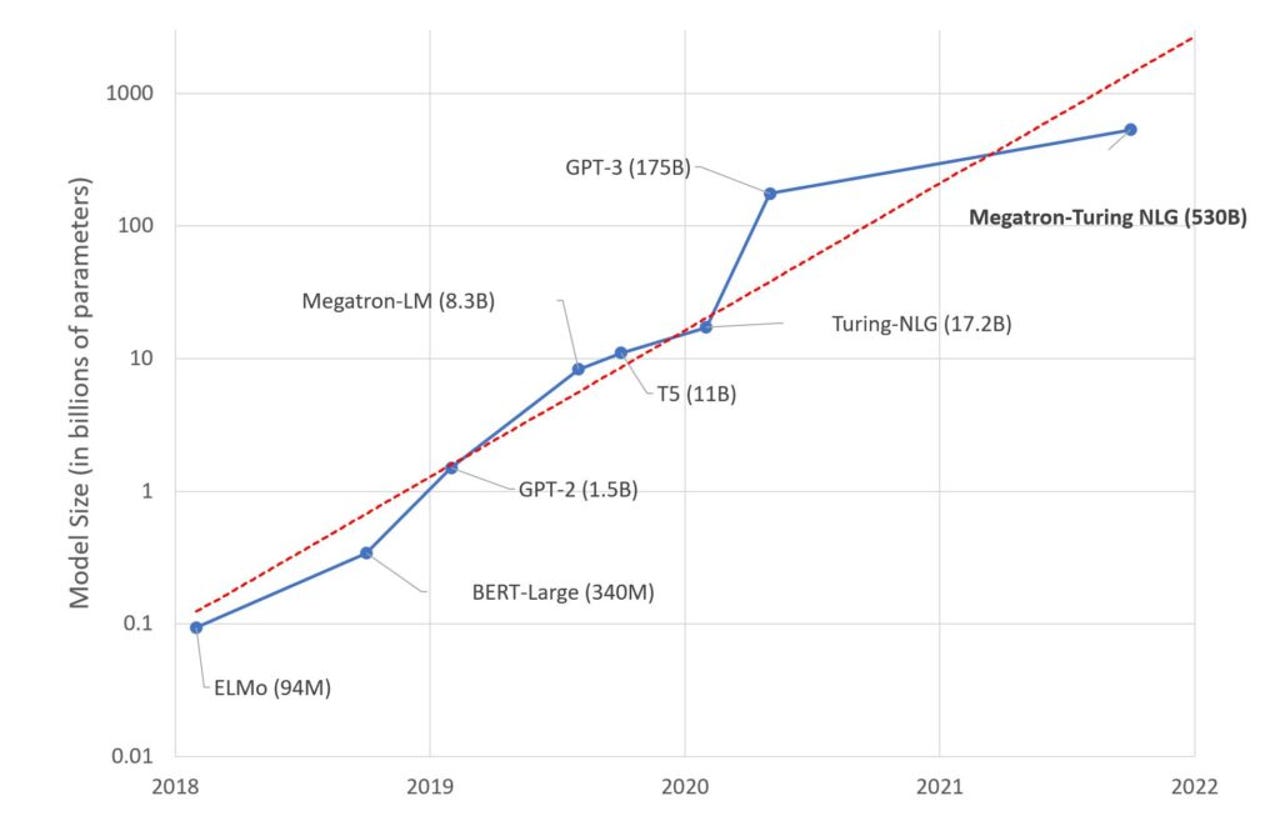
The Megatron-Turing NLG 530B natural langauge processing program, developed by Nvidia and Microsoft, has 530 billion paremeters. The companies say it is the largest natural langage program "trained to convergence," meaning, with its neural weights, or parameters, fully developed so that it can perform inference tasks.
Image: MicrosoftThe figures for various metrics, such as "achieved teraFLOPs" are "real data points," said Kharya, "measured by conducting partial training runs."
The point of a partial training run is to approximate a "miles per gallon" measure like you would with a car, said Kharya, in order for customers to know what it takes to train and deploy a particular model before they commit to doing so.
"Different customers are using different models and they need to estimate, if they were to bring a model size online an Nvidia platform, how much computing resources would they need to invest," explained Kharya, "or if they had a given amount of computing resources, how long would it take to train these models."
The data points in FLOPs can tell a customer for how long they would need a cloud instance, or how large an instance they're going to need for a committed amount of training time.
All that means that Megatron-Turing NLG 530B is the largest model whose neural weights are actually now sufficiently developed to be able to perform on benchmark tests, of which Nvidia and Microsoft offered several results.
The significance of that achievement, said Kharya, is the ability to deploy such a large model across parallelized infrastructure.
Various neural network models developed by Microsoft and Nvidia, including Megatron-Turing NLG 530B, and "1T," a trillion-network model. Figures are form various amounts of training "epochs."
Nvidia"As these models are becoming larger and larger, they can break the memory of a single GPU, and sometimes they don't even fit in the memory of a single server," observed Kharya.
Using the Megatron software to split models between different GPUs and between different servers, and "using both data parallelism and model parallelism," and smarter networking, "you're able to achieve very, very high efficiency," he said.
"That means over 50% of theoretical peak performance of GPUs," said Kharya. "That's a very, very high number, meaning, you're achieving hundreds of teraFLOPs for every GPU."
Competitors to Nvidia such as startup Cerebras Systems have started to discuss the theoretical prospect of training multi-trillion-parameter models to convergence, without actually showing such an achievement.
Asked when Nvidia and Microsoft will train to convergence an actual one-trillion model, Kharya demurred. "Everyone in the industry is working on these really giant models, and it's going to happen," he said. "But by whom and when, well, wait and watch."
Megatron-Turing NLG 530B is not a commercial product, it is a research project between Nvidia and Microsoft. However, Nvidia has a catalog page on its Web site where one can obtain dozens of models made available in containers ready to run, including Transformer-based language models and other kinds of neural networks such as those for computer vision.
The models are "pre-trained," ready to be used for inference, but some customers also enhance the models further with additional training runs on their own data, said Kharya.
 Tags chauds:
Intelligence artificielle
Innovation et Innovation
Tags chauds:
Intelligence artificielle
Innovation et Innovation
Inscrivez-vous par courriel maintenant pour le Stock de Promotion hebdomadaire
100% free, Unsubscribe any time!
Add 1: Room 605 6/F FA YUEN Commercial Building, 75-77 FA YUEN Street, Mongkok KL, HongKong Add 2: Room 405, Building E, MeiDu Building, Gong Shu District, Hangzhou City, Zhejiang Province, China
Whatsapp/Tel: +8618057156223 Tél. : + 33 (0) 3 88 88 20: 0086 571 86729517 Tel à HK: 00852 66181601
Courriel:: [email protected]
 English
English Pусский
Pусский Français
Français Español
Español Português
Português

