Inscrivez-vous maintenant pour un meilleur devis personnalisé!







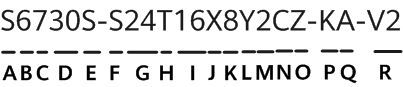

















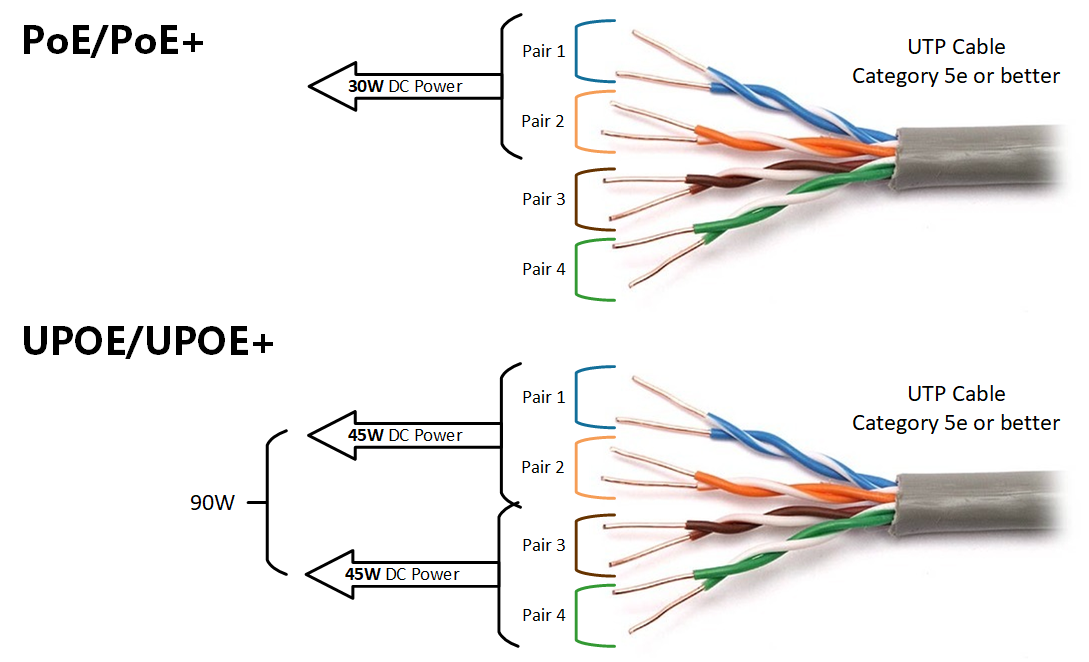
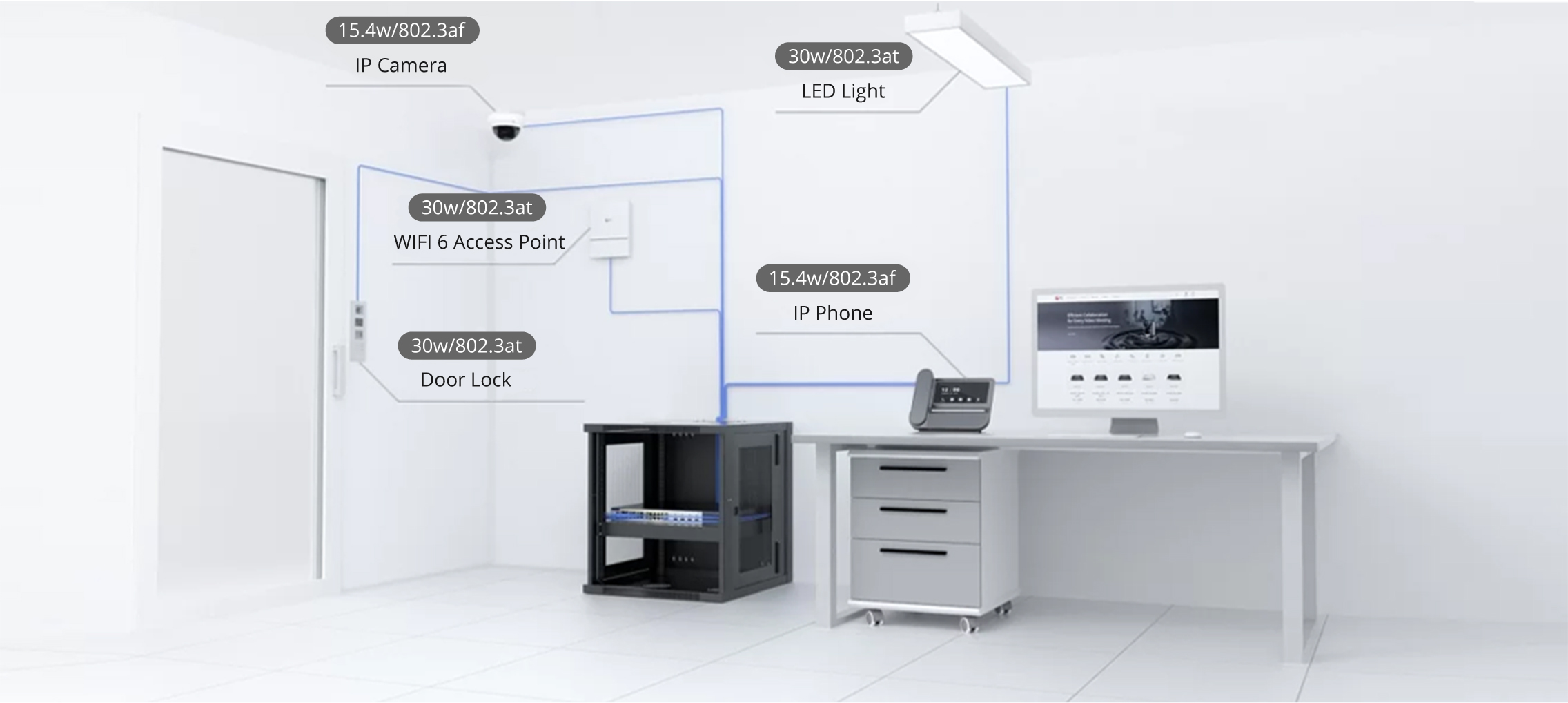




Wall Street is predicting a rough 2024 for Apple's iPhone franchise because of a lack of interesting new hardware features. Could artificial intelligence software make an iPhone 16 shine brighter?
Some Apple stock bulls think so. Morgan Stanley analyst Erik Woodring this month opined that 2024 "will be the year that Apple's 'Edge AI' opportunity comes to fruition," and that it could power the new crop of iPhones this fall to greater heights.
Also:The iPhone 16 Ultra camera will integrate the biggest leap in photos since B&W-to-color
Apple's iPhone sales, led by the current iPhone 15, are expected to decline by about 2% this year, according to estimates compiled by FactSet Systems, to 229 million units, as the current iPhone cycle underwhelms with merely iterative hardware features.
But come 2025, wrote analyst Woodring, current Wall Street expectations for growth of 4%, to 237 million units, could turn out to be 15% higher if an iPhone 16 has enhanced AI capabilities.
"If we are correct, and new LLM-enabled software features drive an upgrade cycle, then we see the potential for up to 15% upside to our FY25 iPhone shipment forecast," wrote Woodring. The acronym "LLM" refers to "large language models" such as OpenAI's GPT-4.
Woodring speculates that the world will see details at Apple's Worldwide Developer Conference this summer, "highlighted by an LLM-powered Siri 2.0 and a broader GenAI-enabled operating system that has the potential to catalyze an iPhone upgrade cycle."
Why is "LLM-powered" such a big deal? To use large language models akin to OpenAI's GPT-4 requires a phone to go back and forth to the network, sending prompts and retrieving responses. Even on a desktop computer with an ethernet connection, the round-trip means waiting a while for a response. In a mobile device on a cellular network, relying on the cloud connection could result in one of those awkward moments where Siri seems brain-dead.
Also: iPhone 15 review: I spent a month with Apple's base model and found it more 'Pro' than ever
Instead, what's needed is to eliminate the cloud reliance and move more of the LLM processing locally, on the device. Apple already has what it calls the "Neural Engine" in the iPhone, a separate collection of circuits for running AI. However, the AI tasks performed by the Neural Engine -- tasks much less demanding than an LLM -- are likely to involve very carefully defined functions such as face recognition, where the use of the circuits has been carefully curated.
Taking an off-the-shelf large language model and running it locally is bound to be a much more demanding task.
Woodring bases much of his enthusiasm about this year's AI on a paper published this month by Apple researchers Keivan Alizadeh and colleagues, titled, "LLM in a flash: Efficient large language model inference with limited memory," which is posted on the arXiv pre-print server.
Also: Humane's aspiring smartphone-killer 'Ai Pin' may be the most 2023 product yet
The crux of the paper is that LLMs take up a lot of memory, and Apple has found a clever way to use the vast storage of the resident flash memory -- the stuff that holds the iPhone's files. With special software, an LLM can be easily moved into and out of main memory, DRAM, with the illusion of having a lot more DRAM than is typical on the phone.
As Alizadeh and colleagues write, the tactics they use with memory "enable running models up to twice the size of the available DRAM," and speed up the making of predictions on a device by as much as 25 times.
The problem the authors tackle is that there just isn't enough DRAM on most mobiles, while LLMs keep getting bigger and bigger. "A 7-billion-parameter model requires over 14GB of memory just to load the parameters in half-precision floating point format, exceeding the capabilities of most edge devices," write Alizadeh and team, referring to the neural "weights" or "parameters," values that are stored in memory that give shape to a trained neural network.
Also: Samsung's new Galaxy S24 beats the iPhone 15 Pro in one very meaningful way
Apple doesn't disclose amounts of onboard DRAM, but the site Everymac cites third-party data suggesting that the iPhone 15 Pro Max has 8GB of DRAM. Samsung's recently unveiled Galaxy S24 Ultra has 12GB of DRAM, according to Samsung.
Much more memory, of course, is available in the NAND flash storage in phones. The Pro Max has a terabyte of memory, as does the S24 Ultra. The greater issue is moving data back and forth. NAND flash is slower than DRAM memory, so fetching data from it each time is slower than operating out of DRAM entirely.
Apple experiments with keeping the neural network in flash memory and putting only some of it in DRAM.
What's more, moving data from the flash memory into the DRAM memory entails a transfer time, which introduces a delay, called latency, between what the user tries to do and the results. That could mean the user waiting seconds between, say, typing into an LLM prompt and getting a response -- just as bad as going to the cloud. Even moving from DRAM into the phone's central processor introduces a delay, the authors note.
Their solution is to use a fundamental aspect of neural networks including LLMs: sparsity. Sparsity means that a lot of those neural weights that make up the neural network are actually empty. They have a numeric value of zero. They can be ignored, therefore, so that only a small number of the total weights need to be fetched from memory.
Also: Buying the Samsung Galaxy S24 for its AI features? Read the fine print first
"LLMs exhibit a high degree of sparsity," write Alizadeh and team. "We exploit this sparsity to selectively load only parameters from flash memory that either have non-zero input or are predicted to have non-zero output."
The authors also come up with many clever techniques aboutwhichof those non-zero weights to call from flash memory, things such as pre-fetching the weights that are most likely to be needed based on the prediction task that the user may trigger next.
The report demonstrates dramatic speed-ups when running two open-sourceLLMs: Meta's Open Pretrained Transformer, and the Falcon series of language models from the Technology Innovation Institute of Abu Dhabi.
Apple was able to reduce the latency of serving large language models.
There's just one problem with the hopes of Woodring and others for an iPhone 16 as a supercomputer for AI: The work in the research paper was done on a Mac. Specifically, Alizadeh and team developed all of their techniques on Apple's "M1 Max" processor, which is only in the MacBook Pro and Apple's Studio desktop. That chip is substantially bigger and more powerful than the "A17 Pro" found in the iPhone 15.
Moreover, as the authors state, their tests don't touch on one of the things that users of pocket computers care most about: battery life. "A critical aspect for future exploration is the analysis of power consumption and thermal limitations inherent in the methods we propose, particularly for on-device deployment," they write.
Also: Apple Silicon, Rosetta, M1, M2, M3, SoC: Why these terms matter to every computer buyer
Nevertheless, the M-series silicon from Apple has generally found its way into mobile devices. The original M1 and M2 chips have ended up in versions of Apple's iPad Pro and iPad Air tablets. That means there is a continuum to both Apple's chips and software efforts such as the kind Alizadeh and team explore.
It's possible that an "A18" processor in an iPhone 16 Pro Max could strike a balance between running smart sparsity and conserving battery life. It's also possible that the kind of approach discussed in the paper could be used with very small versions of LLMs as a first step. Both models tested in the paper by Alizadeh have 7 billion parameters, which makes them fairly small as LLMs go. Apple could go even smaller, below a billion parameters, to preserve energyandmemory usageandCPU usage.
Regardless of what shows up at WWDC, or in September's expected iPhone unveiling, one can presume the structure of the research by Alizadeh and team shows AI is coming out of the cloud and into your pocket sooner or later.
 Tags chauds:
Innovation et Innovation
Tags chauds:
Innovation et Innovation
Inscrivez-vous par courriel maintenant pour le Stock de Promotion hebdomadaire
100% free, Unsubscribe any time!
Add 1: Room 605 6/F FA YUEN Commercial Building, 75-77 FA YUEN Street, Mongkok KL, HongKong Add 2: Room 405, Building E, MeiDu Building, Gong Shu District, Hangzhou City, Zhejiang Province, China
Whatsapp/Tel: +8618057156223 Tél. : + 33 (0) 3 88 88 20: 0086 571 86729517 Tel à HK: 00852 66181601
Courriel:: [email protected]
 English
English Pусский
Pусский Français
Français Español
Español Português
Português

