Inscrivez-vous maintenant pour un meilleur devis personnalisé!

 Fast Shipping To United States
Fast Shipping To United States




























 OceanGate Expeditions
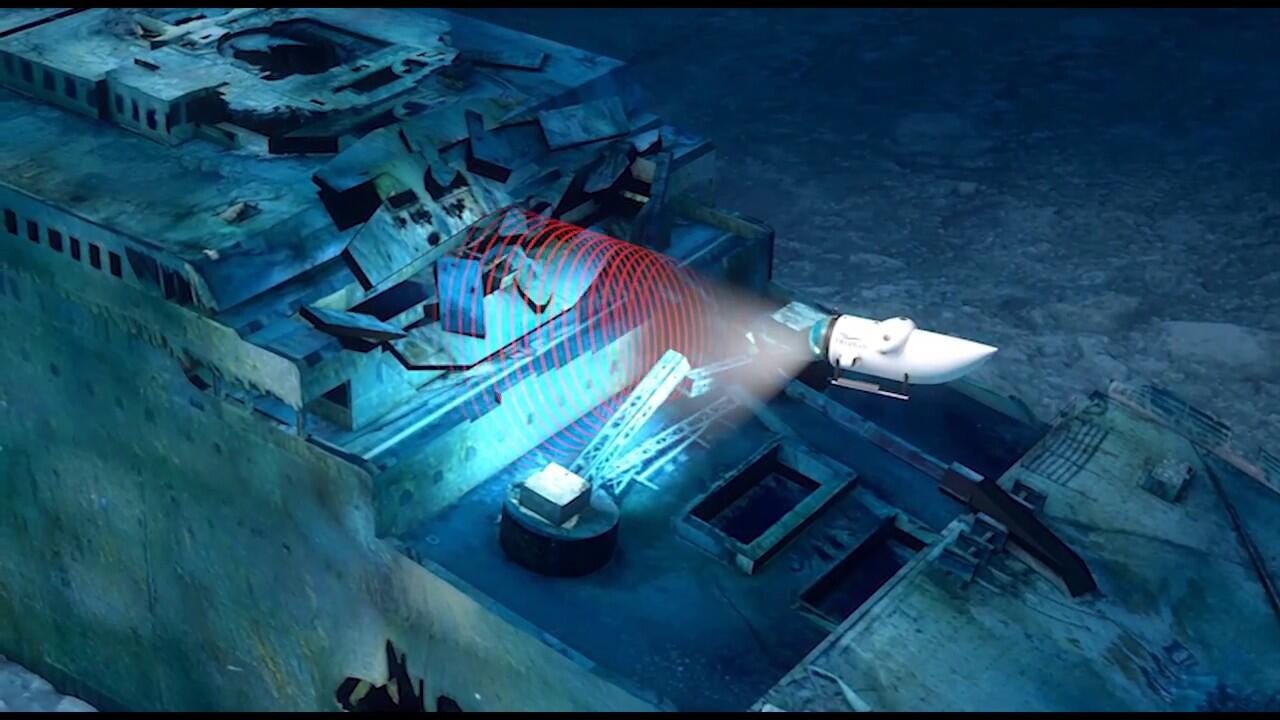
OceanGate Expeditions A researcher has brought video conferencing technology to one of the most remote places on earth: The wreck of the HMS Titanic, which is resting on the seabed 13,000 feet below the surface.
"It is as if we can now carry out video conferences from the abyss," says Alex Waibel, a researcher at Carnegie Mellon University and Karlsruhe Institute of Technology.
Scared yet?
Waibel is an expert in text to speech technology. Currently, the only way for researchers exploring the Titanic wreck or other deep sea targets in submersibles to communicate with the surface is via text messages sent by sonar. Radio signals don't work well underwater, presenting a communications quandary that scientists have been finding workarounds for since WWII.
During a recent OceanGate Expeditions voyage, Waibel narrated his dive and used speech recognition technology to convert what he was saying to transmittable messages. On the surface, the technology Waibel and his team pioneered then resynthesized the crude text messages to video using AI. The result was a near real-time video that used Waibel's voice over a video that looked like his lips moving in sync with the words. These efforts are aimed at aiding natural communication in extreme environments but could have potential in consumer markets as well. Waibel is a Zoom research fellow and advises the company's AI research and language technology development.
"By interpreting and recreating natural voice communication, we are trying to reduce the workload of scientists and pilots in such missions in a natural way, despite the challenges imposed by salt water, operational stress, conversational dialogue and poor acoustic condition," Waibel told CMU's Aaron Aupperlee.
We've written about the tremendous advances and market growth of speech recognition, which is entering an accelerated phase of development and adoption across a number of key sectors. Waibel's work builds on that trend with a delivery mechanism that uses low bandwidth broadcasts (in this case by sonar) to effectively deliver full, albeit synthesized, video to the end user.
The technology uses a synthesized voice that sounds like the speaker, building on advances in AI-powered text to speech technology. One other potential application of the technology is rapid translation from one language to another, where an end user sees a video in a comprehensible language that the speaker doesn't actually know.
 Tags chauds:
Intelligence artificielle
Innovation et Innovation
Tags chauds:
Intelligence artificielle
Innovation et Innovation
Inscrivez-vous par courriel maintenant pour le Stock de Promotion hebdomadaire
100% free, Unsubscribe any time!
Add 1: Room 605 6/F FA YUEN Commercial Building, 75-77 FA YUEN Street, Mongkok KL, HongKong Add 2: Room 405, Building E, MeiDu Building, Gong Shu District, Hangzhou City, Zhejiang Province, China
Whatsapp/Tel: +8618057156223 Tél. : + 33 (0) 3 88 88 20: 0086 571 86729517 Tel à HK: 00852 66181601
Courriel:: info@hi-network.com
 English
English Pусский
Pусский Français
Français Español
Español Português
Português
